어렵게 1 회독을 마친 후 생각이 들었다. 블로그에 따로 정리하지 않으면 머릿속에 저장은 물론 시간이 지나면 스르륵 사라지겠구나 ㅋㅋㅋㅋ
생각이 들어 바로 요약 or 정리 들어간다.
이 글은 전적으로 코어 자바스크립트를 읽고 나름대로 요약한 글이다.

1장은 데이터에 관한 장으로, 자바스크립트가 데이터를 처리하는 과정을 살펴봄으로써, 기본형 타입과 참조형 타입이 서로 다르게 동작하는 이유를 이해하고 적절히 활용하게 되는 게 목표다.
01 데이터 타입의 종류
JS는 기본형(primitive type)과 참조형(reference type)이 존재한다.
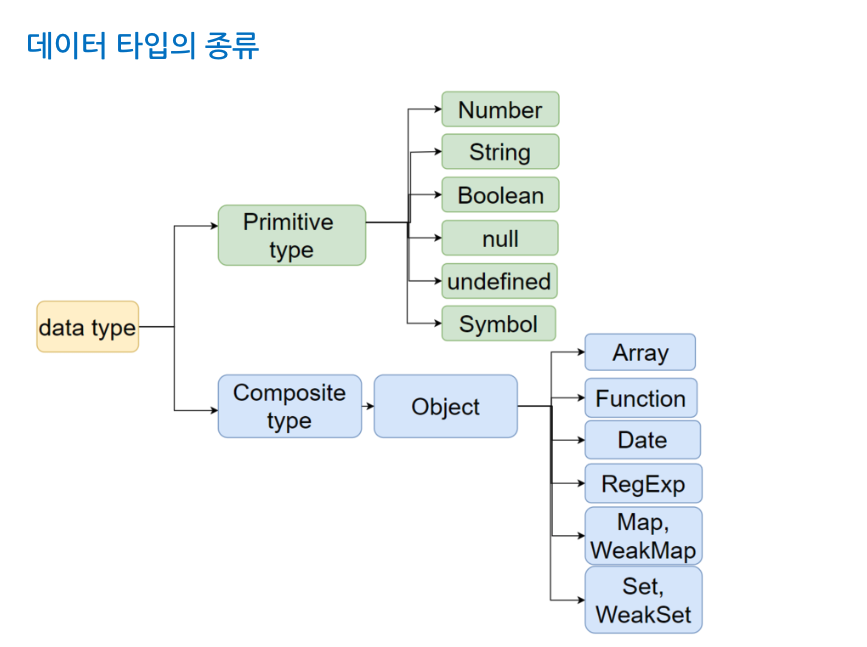
ES6에서 기본형은 Symbol이 추가되었고, 참조형은 Map, WeakMap, Set, WeakSet 등이 추가되었다.
일반적으로 기본형은 할당이나 연산 시 복제되고 참조형은 참조된다고 알려져 있습니다.
엄밀히 말하면 둘 모두 복제를 합니다. 다만, 기본형은 값이 담긴 주 솟값을 바로 복제하는 반면, 참조형은 값이 담긴 주솟값들로 이루어진 묶음을 가리키는 주솟값을 복제한다는 점이 다릅니다.
기본형은 불변성(immutability)을 띕니다. 기본형인 숫자 10을 담은 변수 a에 다시 숫자 15를 담으면 a의 값은 문제없이 15로 변하는데, '변하지 않는다'는 게 어떤 의미인지 잘 와닿지 않는다.
불변성을 이해하기 위해서는 개략적으로나마 메모리와 데이터에 대한 지식이 필요하고, 나아가 '식별자'와 '변수'의 개념을 구분할 수 있어야 합니다.
02 데이터 타입에 관한 배경지식
메모리와 데이터
컴퓨터는 모든 데이터를 0 또는 1로 바꿔 기억한다. 0 또는 1만 표현할 수 있는 하나의 메모리 조각을 비트라고 합니다. 각비 트는 고유한 식별자(unique)를 통해 위치가 확인 가능하다. 그런데 고작 0이나 1만 표현할 수 있는 비트 단위로 위치를 확인하는 것은 매우 비효율적입니다.
한편 매우 많은 비트를 한 단위로 묶으면 이번에는 검색시간은 줄일 수도 있고 표현할 수 있는 데이터의 개수도 늘어나겠지만, 동시에 낭비되는 비트가 생기기도 합니다. 사용하지 않을 데이터를 표현하기 위해 빈 공간을 남겨놓기보다는 어느 정도 제약이 따르더라도 크게 문제가 되지 않을 적정한 공간을 묶는 편이 낫습니다. 이런 고민의 결과로 바이트(byte) 단위가 생겼습니다.
1바이트는 8개의 비트로 구성돼 있습니다. 1비트마다 0 또는 1의 두 가지 값을 표현할 수 있으므로 1바이트는 총 256개의 값을 표현할 수 있고, 2바이트는 16개이므로 65536개의 값을 표현할 수 있다.

C/C++, 자바 등의 정적 타입 언어는 메모리의 낭비를 최소화하기 위해 데이터 타입별로 할당할 메모리 영역을 2바이트, 4바이트 등으로 나누어 정해놓았습니다. 정수형 타입(short)은 -32768 ~ + 32768의 숫자만 허용하는데, 만약 사용자가 그 이상의 숫자를 입력하면 오류가 나거나 잘못된 값이 저장된다. 그래서 이 문제를 해결하기 위해서는 사용자가가 직접 정수형 타입(int)등으로 형 변화를 해줘야 한다.
이런 작업 꽤나 번거롭지만, 메모리 용량이 부족했던 시절은 불가피한 선택이었습니다.
한편 메모리 용량이 과거보다 월등히 커진 상황에서 등장한 자바스크립트는 상대로 적으로 메모리 관리에 대한 압박에 자유로워졌다. 그래서 메모리 공간을 좀 더 넉넉하게 할당했습니다. 숫자의 경우 정수형인지 부동 소 수형인지 구분하지 않고, 8바이트를 확보한다.
우리는 지금 컴퓨터에 숫자형 데이터를 저장하는 방법을 개념적으로 알아보고 있습니다. 앞에서 각비 트는 고유한 식별자를 지닌다고 했습니다. 바이트 역시 시작하는 비트의 식별자로 위치를 파악할 수 있습니다. 모든 데이터는 바이트 단위의 식별자, 더 정확하게는 메모리 주 솟값(memory address)을 통해 서로 구분하고 연결할 수 있다.
식별자와 변수
변수(variable)와 식별자(identifier)를 혼용하는 경우가 많다. 혼용이 가능한 이유는 대부분의 경우 문맥에 따라 무엇을 말하고자 하는지를 유추할 수 있기 때문이지만 둘의 차이를 모른다면 혼란스러울 수 있습니다.
변수는 '변할 수 있는 수'입니다. 영어단어(variable)는 원래 '변할 수 있다'라는 형용사이지만 컴퓨터 용어로 쓸 때는 '변할 수 있는 무언가'로 확장시켰습니다. 여기서 '무언가'란 데이터를 말합니다. 숫자도 데이터이고, 문자열, 객체, 배열 모두 데이터입니다.
식별자는 어떤 데이터를 설명하는 데 사용하는 이름, 즉 변 수명입니다.
03 변수 선언과 데이터 할당
변수 선언
var a;위에 코드를 풀어쓰면, "변할 수 있는 데이터를 만든다. 이 데이터의 식별자는 a로 한다"가 됩니다.
이렇게 보면 변수란 결구 변경 가능한 데이터가 담길 수 있는 공간이라고 생각된다.
컴퓨터가 위에 코드를 받아 메모리 영역에서 어떤 작업을 수행하는 밑에 보여드리겠습니다.
| 주소 | 1002 | 1003 | 1004 | 1005 |
| 데이터 | 이름 : a 값 : |
컴퓨터는 메모리에서 비어있는 공간 하나를 확보합니다.
공간의 이름을 a라고 지정합니다. 여기까지가 변수 선언 과정입니다. 이후에 사용자가 a에 접근하고자 한다면 컴퓨터는 메모리에서 a라는 이름을 가진 주소를 검색해 해당 공간에 담긴 데이터를 반환합니다.
데이터 할당
var a ; // 변수 a 선언
a = 'abc'; // 변수 a에 데이터 할당
var a = 'abc' //변수 선언과 할당을 한 문장으로 표현선언과 할당 나누어 명령하든 한 문장으로 표현하든 자바스크립트 엔진은 결국 같은 동작을 수행합니다.
할당 과정은 a라는 이름을 가진 주소를 검색해서 그곳에 문자열 'abc'를 할당하면 될 것 같습니다.
그런데 실제로는 해당 위치에 문자열 'abc'를 직접 저장하지 않습니다. 데이터를 저장하기 위한 별도의 메모리 공간을 다시 확보해서 문자열 'abc'를 저장하고, 그 주소를 변수 영역에 저장하는 식으로 이뤄집니다.
데이터 할당의 전체 흐름을 그림으로 보여드리겠습니다.
변수 영역
| 주소 | 1002 | 1003 | 1004 | 1005 | |
| 데이터 | 이름: a 값: @5004 |
데이터 영역
| 주소 | 5002 | 5003 | 5004 | 5005 | |
| 데이터 | 'abc' |
1. 변수 영역에서 빈 공간(@1003)을 확보한다.
2. 확보한 공간의 식별자를 a로 지정한다.
3. 데이터 영역의 빈 공간(@5004)에 문자열 'abc'를 저장한다.
4. 변수 영역에서는 a라는 식별자를 검색한다.(@1003)
5. 앞서 저장한 문자열의 주소(@5004)를 @1003의 공간에 대입한다.
왜 변수 영역에 값을 직접 대입하지 않고 굳이 번거롭게 한 단계를 더 거치는 걸까요??
이는 데이터 변화를 자유롭게 할 수 있게 함과 동시에 메모리를 더욱 효율적으로 관리하기 위한 고민의 결과입니다.
문자열은 특별히 정해진 규격이 없습니다. 한글 자마다 영어는 1바이트, 한글은 2바이트 등으로 각각 필요한 메모리 용량이 가변적이며 전체 글자 수 역시 가변적이기 때문입니다.
만약 미리 확보한 공간 내에서만 데이터 변화를 할 수 있다면 변환한 데이터를 다시 저장하기 위해서는 '확보된 공간을 변환된 데이터 크기에 맞게 늘리는 작업'이 선행돼야 할 겁니다. 해당 공간이 메모리 상의 가장 마지막에 있다면 뒤쪽으로 늘리기만 하면 되지만, 중간에 있는 데이터를 늘려야 한다면 뒤에 있는 데이터를 전부 뒤로 옮기고, 이동시킨 주소를 각 식별자에 다시 연결하는 작업을 해야 합니다.
그럼 컴퓨터가 처리해야 할 연산이 많아질 수밖에 없겠죠??
결국 효율적으로 문자열 데이터의 변환을 처리하려면 변수와 데이터를 별도의 공간에 나누 너 저장하는 것이 최적입니다.
문자열 'abc'의 마지막에 'def'를 추가하라고 하면 컴퓨터는 앞서 'abc'가 저장된 공간에 'abcdef'를 할당하는 대신 문자열을 새로 만들어 별도의 공간에 저장하고, 그 주소를 변수 공간에 연결합니다. 기존 문자열에 어떤 변황을 가하든 상관없이 무조건 새로 마뎌 별로의 공간에 저장합니다.
문자열 변환에 대한 메모리 영역의 변화
| 주소 | 1002 | 1003 | 1004 | 1005 |
| 데이터 | 이름: a 값: @5005 |
|||
| 주소 | 5002 | 5003 | 5004 | 5005 |
| 데이터 | 'abc' | 'abcdef' |
다른 예로 500개의 변수를 생성해서 모든 변수에 숫자 5를 할당하는 상황이면, 각 변수를 별개로 인식하려면 500개의 변수 공간을 확보하는 것을 불가피합니다. 그런데 각 변수 공간마다 매번 숫자 5을 할당하려면 하면 숫자형은 8바이트가 필요하니 총 4000(500* 8) 바이트를 써야 할 것입니다. 그 대신 5를 별도의 공간에 한 번만 저장하고 해당 주소만 입력한다면 어떨까요? 그렇다면 총 1008(500 *2 + 8) 바이트만 이용하면 됩니다. 이처럼 변수 영역과 데이터 영역을 분리하면 중복된 데이터에 대한 처리 효율이 높아집니다.

'책 정리' 카테고리의 다른 글
| 코어 자바스크립트 1장 데이터 타입(06,07) (0) | 2022.06.20 |
|---|---|
| 코어 자바스크립트 1장 데이터 타입(05 불변객체) (0) | 2022.06.13 |
| 코어 자바스크립트 1장 데이터 타입(04) (0) | 2022.06.12 |



댓글